Fact, Fiction & The AI Future

Over the past few weeks, I’ve presented at multiple events and attended a half-dozen talks/panels on Generative AI – from how GenAI will revolutionize marketing (such as transforming SEO to “AIEO”), to innovative applications in fields as diverse as Memory/Alzheimer’s care and credit scoring.
Put simply: the AI craze is still in full swing.
I’ve had dozens of conversations with CMOs, CEOs, Investors & PE/VC GPs in the past few months – all of whom have asked remarkably similar questions:
- Where is all this going?
- How much of the hype is real?
- Where are impacts of this tech most likely to be felt first? Second?
- What could be real, but isn’t yet?
- What’s fantasy-land nonsense?
- How will regulation play into the development roadmap?
- What are we missing?
I’ve compiled my notes and responses from many of those conversations and consolidated them below.
The Gen AI Foundational Principles:
Before diving into the bigger questions, let’s set the stage with some basic principles. At a foundational level, Generative AI is a type of artificial intelligence capable of generating or modifying content (speech, text, images, videos) via (among other things) large language models. Those models ingest massive amounts of training data (usually the C4 or some variant thereof), then use advanced statistics to uncover the latent patterns in the training data. Those patterns are then used to generate novel content by probabilistic modeling (i.e., predicting the next word based on the previous word).
In essence, Generative AI reduces conceptual/logical problems to statistics problems.
The first iteration of machine learning (we can use image recognition or voice search as examples) relied on people as a primary point of leverage: someone had to manually label every image of a “cat” or a “dog” as such, or write the Alexa App that told you the Sixers score. In order for the application to work, a person needed to create a set of rules, commands and workflows to “understand” an input and provide a relevant output. You could (in theory) ask an image recognition program for a picture of a cow, and it would “understand” the question – but it could only respond if someone had actually labeled a few thousand (or a few million) pictures of cows and provided those to the model. The same thing is true of Alexa: you could ask it anything, but it could only respond adequately if you asked it for something for which someone had built an app.
What makes Generative AI exciting is that it automates both sides of this equation – the machine can build the machine (or, more accurately, it can build something that resembles the machine). You no longer need a person to build the application or write the rules or label the images.
While this is all well and good, reducing every problem to a statistics/probability problem does come with limitations, namely:
- Not all questions are suitable for probabilistic answers – There are some domains and types of questions where there are black-and-white, true-or-false answers. The speed of light is ~299,792,458 m/s. That’s not open to probabilistic determination. It’s a law of the universe.
- Mimicry vs. Creation – This hasn’t gotten the attention it deserves, but there’s a material difference between a machine creating something that resembles a pattern (which is largely what LLMs like ChatGPT do), and creating something novel. While it’s true that ChatGPT can create an image of a lion holding a scepter, standing on a balcony of a starship overlooking Earth, the ingenuity is (largely) in the prompt, not in the assembly of the components into something coherent.
- Some errors matter more than others – In some domains (like literature or marketing), being 99% accurate/right is wonderful; no one cares if there’s a minor creative oversight in the color of a character’s coat or the fluff copy on a landing page. But, if you’re an attorney or a developer, and the 1% error has the unfortunate side effect of making the entire contract/program non-viable – that’s a much different problem.
- Sometimes the statistically correct answer isn’t the societally correct answer – I was recently speaking at Loyola University – Maryland on a AI + Financial Ethics panel, and one of the topics we discussed was what happens if an unsavory character tries to use AI to find ways to circumvent fair lending regulations? Should the model return an answer that is responsive to the query, thereby providing the character with the modus operandi to enact their nefarious scheme? Presumably there are some mechanisms that would be appropriate/fit the bill for this (and would thus be statistically correct), but should the model provide that answer?
- It’s a big world – but training data doesn’t always reflect it – Another particularly thorny challenge with LLMs pertains to the data on which they are trained. To be blunt, the C4 is (overwhelmingly) Western, English and predominantly authored by people with degrees, stable careers and the like. And, as any linguistic scholar will tell you, linguistic patterns vary dramatically across socio-economic, geographic and political spectrums – which means that LLMs might produce content that sounds like what those groups would say, but resemblance may not be sufficient.
Where Is This All Going?
All of this gets us to a place where we have an incredibly exciting technology – likely the enabling layer of the next 10-20 years – but have little idea what that actually means, and even less idea what that will look like. In many ways, this is the same place we were in back in the early-mid 90s, when some people had cell phones – most people knew there was something there, but few (if any) of us imagined the iPhone, much less the app store.
That is, in many ways, a parallel to where I think this is all going: GenAI will be an enabling layer, just like mobile, the internet, the GUI and databases before. It’s the thing on which the next decade or two of technology will be built – and now, as then, we’re still working out many of the fundamental questions:
- Do foundational models exhibit network effects – i.e., will foundational models tend toward consolidation (as we saw with social networks, search engines and telephone networks), or will we have an equilibrium where each tool maintains its own model, for its own reasons, and the advantage of doing so is sufficient to justify the cost?
- When building on FMs, how thin a wrapper is too thin? Right now, most tools that use GenAI are (basically) using API calls. Is that viable? Probably not. But it’s what we’ve got right now.
- Where are the areas where GenAI makes the most sense? The least sense? There’s been a lot of hype about GenAI in industries like advertising, but that seems to be a product of two things: (1) people in advertising have a use-case that is uniquely well-suited to GenAI (read: forgiving of hallucinations) and (2) people in advertising tend to be more comfortable + proficient in the kinds of things (content production, social media, etc.) that create the perception that “everyone” is doing it.
- What is the end-state of all this? There’s a prevalent thesis that, in relatively short order, we’ll have autonomous agents capable of doing just about anything for us – if you want to submit a zoning variance, or plan a wedding, or file your taxes, you just ask the LLM-powered agent and it’ll identify the data needed, built the workflows, acquire the data, run the requisite operations and give you the answers/solutions/event plans.
I don’t think the above thesis – that LLMs-as-Agents will run our lives – is correct. The reasons why are a perfect illustration of where the hype diverges from the reality:
First, there’s the “technical” problem: LLMs are nowhere near good enough to do many basic tasks, let alone the orders-of-magnitude more complex ones described above. Error rates are improving (mostly), but they’re still far too high for any mission-critical tasks (such as taxes, or bookkeeping, or cybersecurity). This is further compounded by the fact that certain classes of tasks are, by definition, ill-suited to probabilistic systems: in some cases, like advertising from above, looks correct can be acceptable. In other cases, like medicine, or taxes, or engineering, looks right is just wrong. This is probably the simplest of the three issues – technology will improve, we’ll develop new ways to mitigate errors, we’ll integrate deterministic systems with probabilistic systems to ensure these systems can go from looks correct to is correct. At some level, these are solvable problems – but solvable isn’t the same thing as solved. And anyone who has used Claude or Gemini or ChatGPT knows these are far from solved today.
Second, there’s the Genie problem: if you’re allowed to ask for anything, what do you ask for? GenAI is exciting because it can do just about anything you ask it to – the challenge is determining what to ask.
Thus, in order for these tools to be helpful, we (people) need to identify that a process is performed often enough to justify automating it, that the process is capable of being automated, and that automation has the capability to perform the task at an acceptable level of accuracy.
There are two challenges with this: (1) people are – generally speaking – bad at this type of process identification and – perhaps most importantly (2) people are not particularly fond of doing things that could be in direct contrast to their own self-interest.
Historically, the solution to (1) has been for someone to identify a process/problem that fit the criteria above, develop a piece of software (an app, a SaaS product, whatever), then – and most crucially – sell the solution to a relevant target market. The delusion that most people will see your new product and “get it” is both pervasive and wrong: the law of diffusion of innovation is real. Adoption is difficult. Just because we now have a tool (GenAI) that can automate a material part of development doesn’t mean that either the identification or the adoption parts get any easier; to the contrary – they get harder. If anyone can build anything, then everyone will try to build everything; product will no longer be a differentiator in SaaS.
Third, and finally, we have the “people” problem: as if the tech and the use cases weren’t enough, there’s the active resistance from large segments of the potential user base. That resistance comes in several forms, from economic self-interest to more principled opposition:
On the economic self-interested side, there’s been a deluge of sensational headlines over the past year. I’ve included just a few examples below:
- GenAI will replace 95% of marketing related tasks (Sam Altman, 2024)
- AI will eliminate 85M jobs by 2025 (World Economic Forum, 2024)
- 10% of US Workers could lose their jobs to GenAI (US Economic Council, 2024)
It isn’t difficult to figure out why people in many industries might be hesitant to embrace this technology if they think it’s going to make them irrelevant or put them out of a job – no one likes training their replacement. This fear, in particular, makes identifying the processes where automation can be of assistance exponentially more difficult, because the people who actually know the process are unwilling to share the details of it.
On the philosophical side, there are legitimate questions about everything from Intellectual Property (Does using copyrighted data in training, but not production, constitute a copyright violation? Can LLM outputs be copyrighted?) to user privacy, to the levels of harm these systems could create should they go rogue.
Regulators have been particularly keen on some of those larger, more philosophical questions – with the UK Competition & Markets Authority recently publishing a series of reports (including an April 2024 Update Paper) outlining key risks to “fair, open and effective competition”, along with updates to the AI Principles that are intended to guide the development of Foundational Models. This follows the EU’s Trilogues (the EU AI Law), along with the US’s voluntary AI Commitments and some state-level attempts at GenAI Regulation.
The challenge with all of these regulations and philosophical objections is that we’re still working out what GenAI is and what it can be – so this is all a bit like trying to regulate the number of seats in a car in 1890. Sure, you could do it. But doing so might hinder the creation of the bus, which was (undoubtedly) a good thing for millions of workers and for millions of business owners.
Beyond the specifics, I don’t think any regulator has any idea what this technology is, because most of the people making it don’t, either. We’re talking about chaotic systems that operate at levels of complexity unintelligible to the smartest people on the planet. This is, in some ways, the tradeoff that comes when the machine can make the machine: we don’t know how it does it.
With Excel, you can click into a cell, review each operation, determine the relevant references and come to an understanding as to how the value of the cell was calculated. Going a step further, that same understanding will allow you to predictably alter the value of the cell by adjusting the formula in it or the values of the referenced cells. Excel is a deterministic system. That’s not the case with ChatGPT or Gemini or Claude; the user has no idea how or why any of these models provides the response they do, and they have little awareness of how changes to the prompt (the input) will change the output, or even if the same exact prompt will produce the same output at a subsequent time.
And, more directly: no amount of regulation is going to stop a certain set of actors from continuing down this path. That leaves two options: try to be first, or try to be better. It’s easier to just be first.
What About The Specifics?
If we move from the theoretical to the more tactical, there are areas where LLMs have a great deal of promise, and areas where they’re likely to struggle. From a broad perspective, GenAI tools are fantastic at a certain classes of tasks, primarily those where pattern-matching is at the forefront:
- Language Translation
- Personalization
- Stylized Writing (i.e. write X in the form of Y)
- Mimicking Dialogue
- Speech Recognition
- Correcting Spelling & Grammar
- Classification
- Simplifying Complex Content
- Question Answering
- Casual Interactions / Conversations
This particular set of skills translates readily into a class of applications, like content creation (or, content repurposing) for marketing/advertising, summarizing/reporting the news (we’ve already seen entire newsrooms laid off), creating graphics or graphical works, laying out text, formatting powerpoints, writing code, performing data science tasks (segmentation, statistical analysis, visualization, etc.), sorting lists, and so on.
The impacts of GenAI are already present in many fields where these applications are prevalent – but I’m unconvinced that this is actually going to mean a reduction in jobs. This has the hallmarks of a Jevon’s Paradox situation. If you’re unfamiliar with the reference, the Jevon’s paradox occurs when technological progress increases the efficiency with which a resource is used, but the falling cost of use creates a sufficient increase in demand such that the total resource use increases, rather than decreases.
The same thing is true here: if GenAI + 1 marketer can do the same amount of work as a team of 10, will a company: (a) fire all but 1 marketer and do the same work for ~15% the cost (the company will probably have to give the 1 person retained a raise) or (b) keep the team and do 100x the marketing? The most likely answer is that the company will just do 100x the marketing.
On the flip side, there are many tasks at which GenAI tools are notoriously poor:
- Current Events
- Common Sense
- Math/Counting (Particularly Advanced Math)
- High-Level Strategy
- Reasoning & Logic
- Emotional Intelligence
- Understanding Context
- Understanding Concepts
- Representation
- Humor
- Black-Swan Scenarios
- Being 100% Factual/Accurate
Where things get interesting is that many of the roles referenced above – journalist, marketer, data scientist, coder, etc. – include many of these things, too. You can’t just let ChatGPT write news articles all the live-long day, or you’ll end up with a lot of lawsuits in short order.
So, Where Does That Leave Us
All of this puts us in a situation where we can both see glimpses of a future, but those glimpses are distorted and incomplete. We’re nowhere near the place where AI Maxis claim on Twitter/LinkedIn. 10% or 20% of the workforce isn’t being replaced in the next 2 years. Anyone who thinks it is has never bought or sold enterprise software – everything is decided on 4x sequential 18-month cycles: the first 18 months is the pilots; the second 18 months is the official enterprise budgeting + procurement; the third 18 months is the implementation and the fourth 18th months is when people actually use it. We’ve just started the first 18 month cycle.
And just like the wide-eyed tech people at a company can talk excitedly about what things will be like when a new technology is fully adopted, the reality is that most of the people they’re talking to won’t be there when it finally is complete.
As for the claims that AI is fundamentally changing how we search the internet: there’s little data to support that claim. Here’s the interest over time in “ChatGPT” (a good proxy of adoption):

Similarly, here’s the share of search:
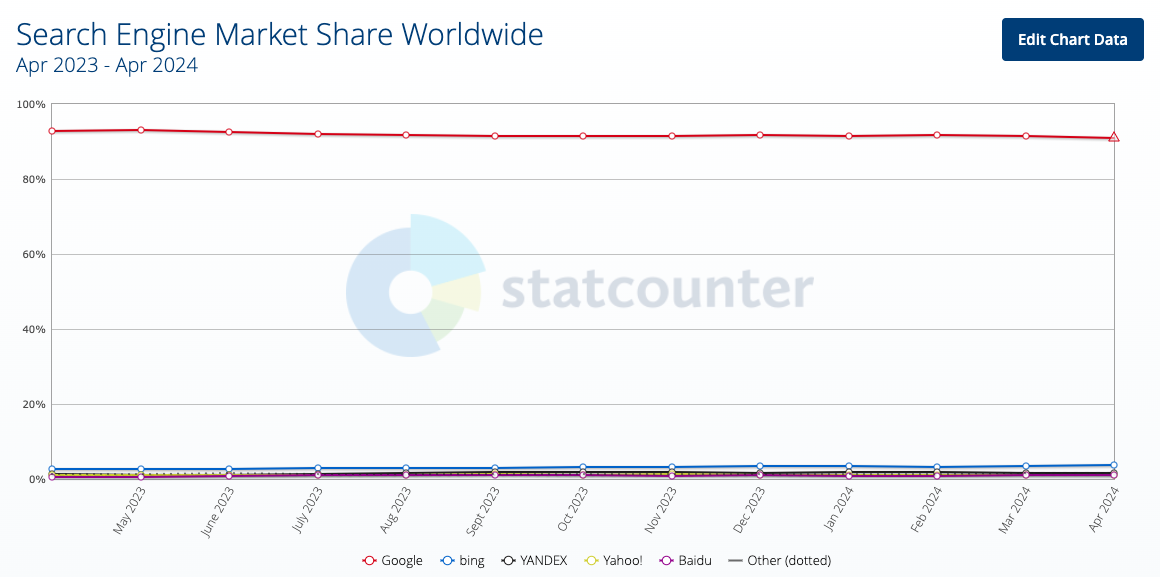
The reality is that most people are not using GenAI as a replacement for search; they may be using the Generated Featured Snippet, but they’re doing so on traditional search engines. Maybe that will persist, maybe it won’t. But if I’m certain of one thing, it’s that the general population changes at a far slower rate than what you read on LinkedIn. Just like it took decades to go from the GUI and VisiCalc to Excel on laptops, so too will it take far longer than most futurists predict to bridge the gap between the hype + the reality of GenAI.
There will come a day when GenAI can function as a true, autonomous agent. But that day isn’t here yet, and it won’t be here tomorrow. So between now and then, our best option is to figure out what the best use-cases for GenAI tools are, help it build the right workflows to automate those processes, and free up more of our time to do higher level, strategic work – or just enjoy a few more hours of sunshine.
Cheers,
Sam

